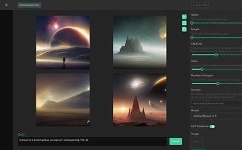



Stable Diffusion 是目前最具影响力的开源 AI 图像生成模型,由 Stability AI 发布并持续迭代。凭借完全开源的生态、丰富的插件扩展和本地化部署能力,它已成为设计师、开发者与 AI 绘画爱好者的首选工具。本文将从安装部署、核心概念、提示词编写、模型选择、采样参数、ControlNet 扩展到优缺点分析,带你系统掌握 Stable Diffusion 的深度使用方法。
下载与安装
本地部署方式
Stable Diffusion 提供三种主流本地部署方案,用户可根据技术水平选择:
1. Stability AI 官方方案
通过 Hugging Face 或 GitHub 下载官方权重文件,配合 Python 环境手动搭建推理管线。适合有编程基础的开发者,灵活性最高但配置较繁琐。
2. AUTOMATIC1111 WebUI
目前用户量最大的图形化界面,基于 Gradio 构建,插件丰富,操作直观。通过一键安装脚本即可在 Windows/Linux/macOS 上快速部署,是新手首选。
3. ComfyUI
基于节点式工作流的界面,通过连接不同功能节点构建生成流程。学习曲线较陡但灵活性极强,适合需要精细控制的高级用户。
硬件要求
| 配置项 | 最低要求 | 推荐配置 | 高性能配置 |
|---|---|---|---|
| 显卡 | NVIDIA 4GB 显存 | NVIDIA 8GB 显存 | NVIDIA 12GB+ 显存 |
| 型号示例 | GTX 1650 | RTX 3060 / 4060 | RTX 4080 / 4090 |
| 内存 | 8GB | 16GB | 32GB |
| 硬盘空间 | 10GB | 30GB | 100GB+(多模型) |
| 操作系统 | Windows 10 64位 | Windows 11 / Ubuntu 22.04 | 同左 |
云部署方案
对于没有高性能显卡的用户,可选择云部署方案。主流平台包括 RunPod、Google Colab(免费但限时长)、AutoDL 及阿里云/腾讯云 GPU 实例,按小时计费,适合偶尔使用。
本节小结: 新手推荐使用 AUTOMATIC1111 WebUI 一键部署,搭配 RTX 3060 及以上显卡即可流畅运行;无显卡用户可选择云部署方案按需使用。
核心概念
扩散模型原理简介
Stable Diffusion 基于潜在扩散模型(Latent Diffusion Model),核心思想是在低维潜在空间中进行加噪与去噪。训练阶段,模型学习从纯噪声中逐步还原清晰图像;推理阶段,根据文本提示词引导,从随机噪声经多步去噪生成目标图像。相比像素空间直接操作的模型,潜在扩散大幅降低了计算开销。
四大核心功能
文生图(txt2img): 输入文字描述,AI 从零生成对应图像。这是最基础也是最常用的功能,适合概念设计、插画创作等场景。
图生图(img2img): 在已有图像基础上,通过提示词引导进行风格转换或内容修改。去噪强度(Denoising Strength)控制变化幅度,值越高与原图差异越大。
局部重绘(Inpaint): 对图像的特定区域进行涂抹遮罩后重新生成,其余部分保持不变。常用于人物换装、背景替换、瑕疵修复等精细编辑。
高清放大(Extras): 使用算法对低分辨率图像进行超分辨率放大,常用算法包括 ESRGAN、SwinIR 等,可将图像放大 2-4 倍同时保持细节清晰。
本节小结: 理解扩散模型的去噪原理有助于合理设置采样参数;四大核心功能覆盖了从生成到编辑的完整工作流。
提示词编写
正向提示词结构
高质量的正向提示词通常遵循以下结构顺序:
主体 + 细节描述 + 环境背景 + 艺术风格 + 质量修饰词
例如:1girl, long silver hair, blue eyes, white dress, standing in a flower field, sunset lighting, anime style, masterpiece, best quality, ultra-detailed
常用质量词
| 类别 | 常用提示词 |
|---|---|
| 画质 | masterpiece, best quality, ultra-detailed, highres |
| 光影 | cinematic lighting, volumetric light, rim lighting |
| 构图 | dynamic angle, close-up, full body, wide shot |
| 风格 | anime style, photorealistic, oil painting, watercolor |
| 渲染 | 8k, 4k, ray tracing, octane render, unreal engine |
负面提示词配置
负面提示词用于排除不希望出现的内容。通用负面提示词模板:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, blurry
权重语法
使用 (word:权重值) 调整关键词的重要程度:
(red hair:1.5)—— 将”红发”权重提升至 1.5 倍(blurry:0.5)—— 将”模糊”的负面影响降低至 0.5 倍((masterpiece))—— 简写形式,等同于(masterpiece:1.1)
权重值建议范围在 0.5-1.5 之间,过高会导致画面失真。
本节小结: 提示词是控制生成结果的核心手段,遵循”主体优先、质量词收尾”的顺序编写,善用权重语法精确调控画面元素。
模型与LoRA
大模型(Checkpoint)选择
大模型决定了生成图像的基础风格与质量。主流模型按风格分类:
| 风格类型 | 代表模型 | 适用场景 |
|---|---|---|
| 写实摄影 | Realistic Vision, ChilloutMix | 人像摄影、产品图 |
| 二次元动漫 | Anything V5, Counterfeit | 动漫插画、角色设计 |
| 概念设计 | DreamShaper, RevAnimated | 概念艺术、创意设计 |
LoRA 微调模型
LoRA(Low-Rank Adaptation)是一种轻量级微调技术,通过小体积文件(通常 10-200MB)对大模型进行风格或角色定制。使用时在提示词中通过 <lora:模型名:权重> 语法调用,权重建议 0.5-0.8。LoRA 可叠加使用,但总数不宜超过 3-5 个,否则容易产生冲突。
VAE 选择
VAE(变分自编码器)负责图像编码与解码过程,影响色彩饱和度和细节还原。推荐使用 vae-ft-mse-840000 或 kl-f8-anime2,前者适合写实风格,后者适合二次元风格。
Embedding 文本嵌入
Embedding(又称 Textual Inversion)通过训练将特定概念编码为向量,使用时以特殊标记嵌入提示词。常用于固定角色面部特征、特定物品或艺术风格。
本节小结: 大模型定基调,LoRA 加风格,VAE 管色彩,Embedding 锁特征,四者配合使用可精确控制生成效果。
采样参数
采样器对比
| 采样器 | 特点 | 适用场景 | 推荐步数 |
|---|---|---|---|
| Euler a | 速度快,创造性高 | 快速预览、创意探索 | 20-25 |
| DPM++ 2M Karras | 画质与速度均衡 | 日常通用,推荐首选 | 20-30 |
| DPM++ SDE Karras | 细节丰富,速度较慢 | 高质量精细生成 | 25-35 |
| DDIM | 确定性采样,可复现 | 图生图、重绘修复 | 30-50 |
采样步数(Steps)
采样步数决定了去噪过程的精细程度。步数过低画面不完整,过高则浪费算力且效果提升有限。配合 DPM++ 2M Karras 采样器,20-30 步通常已能获得优质结果。
CFG Scale 引导系数
CFG Scale(Classifier Free Guidance)控制提示词对生成结果的引导强度。值越高画面越贴近提示词,但超过 15 会导致色彩过饱和和画面崩溃。推荐范围 7-12,写实风格建议 7-9,二次元风格建议 9-12。
生成尺寸
默认推荐 512×512(SD 1.5)或 512×768(竖版)。尺寸过大会导致画面出现重复元素,建议先用小尺寸生成再通过 Extras 高清放大。SDXL 模型原生支持 1024×1024。
本节小结: 日常使用推荐 DPM++ 2M Karras + 25 步 + CFG 7-9 的组合,在画质和速度之间取得最佳平衡。
ControlNet 扩展
ControlNet 是 Stable Diffusion 最强大的扩展插件之一,通过引入额外条件图像实现对生成过程的空间控制。
Canny 边缘检测
输入一张参考图,Canny 算法提取边缘轮廓后引导 AI 沿边缘生成图像,适合建筑线稿转化、产品造型设计等场景。
OpenPose 姿势控制
通过 OpenPose 骨架检测提取人物姿态信息,引导 AI 生成指定姿势的人物。是角色插画、动态场景创作的利器,可精确控制肢体动作和手势。
Depth 深度图
利用深度图提供场景的空间层次信息,AI 根据远近关系生成具有正确透视的图像,适合室内设计、场景概念图等创作。
Segmentation 语义分割
通过语义分割图标注图像中不同区域的类别(人物、背景、物体等),引导 AI 按区域生成对应内容,适合复杂场景的布局控制。
线稿上色
将手绘线稿作为 ControlNet 输入,AI 在保持线条结构的基础上自动上色,配合提示词指定色彩风格,可将黑白草图快速转化为彩色作品。
本节小结: ControlNet 将 Stable Diffusion 从”盲盒式生成”升级为”可控式创作”,Canny 和 OpenPose 是最常用的两个预处理器,建议优先掌握。
优缺点分析
优点
- 完全开源免费,无使用次数限制,无审查机制
- 支持本地部署,数据隐私有保障
- 插件生态丰富(ControlNet、Deforum、AnimateDiff 等),功能可无限扩展
- 模型资源庞大,涵盖写实、二次元、设计等多种风格
- 可精细调控每个生成参数,专业可控性极强
- 支持图生图、局部重绘等编辑功能,工作流完整
缺点
- 本地部署对硬件要求较高,入门门槛相对较高
- 学习曲线陡峭,提示词编写和参数调优需要大量实践
- 生成速度依赖显卡性能,低显存设备体验较差
- 默认模型在生成文字和复杂构图方面仍有不足
- 部分模型存在版权争议,商用需注意授权问题
与 Midjourney 对比
| 对比维度 | Stable Diffusion | Midjourney |
|---|---|---|
| 开源性质 | 完全开源 | 闭源商业产品 |
| 使用门槛 | 较高,需自行部署 | 较低,Discord 即用 |
| 生成质量 | 依赖模型和参数调优 | 开箱即用,审美稳定 |
| 可控性 | 极强(ControlNet 等) | 较弱(依赖提示词) |
| 费用 | 免费(硬件成本) | 订阅制 10-60 美元/月 |
| 隐私性 | 本地运行,完全私密 | 云端处理 |
| 扩展性 | 插件生态丰富 | 功能固定 |
| 适用人群 | 专业用户、开发者 | 设计师、普通用户 |
本节小结: Stable Diffusion 在可控性、扩展性和成本方面优势显著,适合需要精细控制和深度定制的专业用户;Midjourney 则在易用性和审美一致性上更胜一筹。
写在最后
Stable Diffusion 不仅仅是一个图像生成工具,更代表了一种全新的创作范式。从 txt2img 的灵感捕捉到 ControlNet 的精准控制,从 LoRA 的个性化定制到 ComfyUI 的流程自动化,这套开源生态为创作者提供了前所未有的可能性。
学习 Stable Diffusion 是循序渐进的过程:先掌握基础安装和提示词编写,再深入理解采样参数与模型选择,最后通过 ControlNet 实现专业级创作。AI 绘画技术仍在快速迭代,SDXL 等新版本不断推陈出新,保持学习热情,你将在这条创作之路上走得更远。








暂无评论内容